
【この連載について】
この連載では、「1週間でGoogleアナリティクス4の基礎が学べる本」を執筆されているウェブ解析士のみなさん(GA4アベンジャーズ)を中心に、初心者が引っかかりがちな疑問・トラブル解決の基礎知識から、知っておきたい役立ちノウハウ、解析の設定事例、個々の機能解説、最新のホットな話題までをお届けします。
今回は、メンバーズのデータアドベンチャーカンパニーに所属するデータアナリスト河村悠佳さんによる解説です。
【今回のポイント】
- BigQueryやSQLを知ろう
- GA4のデータ構造とよく使うクエリを知ろう
- データの特徴(1):GA4のデータはネスト(入れ子)の構造になっている
- データの特徴(2):GA4のデータはevent_dateの日付ごとにテーブルが作成されている
- データの特徴(3):イベントが発生した日・時間を記録している「event_date」や「event_timestamp」は日付や時間の形のデータ型ではない
- BigQueryを使ってGA4のデータを扱う練習をしよう
 河村
河村GA4からは無料版でもBigQueryにアクセスログのデータをエクスポートできるようになりました。SQLを使う必要はありますが、BigQueryのエクスポートデータを直接扱うことで、標準レポートや探索の機能に縛られずにデータを抽出・集計して分析することができます。
しかし、「SQLやBigQueryにいままで触れてこなかった」「BigQueryの使い方がわからない」「SQLの書き方がわからない」という方もいらっしゃるのではないでしょうか。
そこで、今回は「BigQuery」を使ってGA4のデータを扱い分析するときに、押さえておくべき基本的なポイントをお伝えしていきます!
BigQueryやSQLを知ろう
BigQueryを使ってデータ活用を推進しよう
BigQueryとはGoogleが提供するクラウド型データウェアハウスのプロダクトで、SQLというデータを操作するための言語を用います。
UAでは有料版のGoogleアナリティクス360でのみBigQueryへのエクスポートが可能でしたが、GA4からは無料版でもBigQueryにデータをエクスポートできるようになりました。
参照元BigQuery の概要 | Google Cloud
参照元料金 | BigQuery: クラウド データ ウェアハウス | Google Cloud
BigQueryを使用するメリット・デメリット
メリット
BigQueryを使用することで、以下のようなデータ活用が可能になります。
- GA4のアクセスログデータを他のデータと紐づけて分析する
- SQLを使って集計したアクセスログデータをBIツールに連携して分析や可視化をする
GA4とBigQueryを併用することで、上記2点のようなデータ活用を推進することにつながり、GA4のUI画面で集計されたアクセスログだけを見るよりも、他データと組み合わせたりBIツールで可視化したりすることで、よりアクセスログデータから読み取れることが増えます。
そして、アクセスログデータから得られる示唆も増えて、マーケティング活動における改善や挑戦に取り組む幅も広がることがメリットと考えられます。
デメリット
GA4のデータ構造を理解することに加えて、データベースやSQLなどのエンジニアリング領域の知識が必要になってきます。
またBigQueryは、従量課金制で使用するツールになるため、データ量や扱うクエリの量に応じて使用料金が発生するという点も考慮が必要になってきます。
このようにコストがかかることがデメリットと考えられますが、データ活用やデータドリブンマーケティングを推進していくためにはデータベースやSQLのスキルは重要になってくるので、GA4のデータをBigQueryやSQLを用いて学習を始めてみることはとてもオススメです。
SQLを知ってクエリを書いてみよう
続いて、BigQueryを使用する際に用いる「SQL」という言語について簡単に説明します。SQLはデータを操作する専用の言語です。もう少し具体的に説明すると、SQLという言語で命令文を書いてデータベースに送ることで、以下のようなことができます。
※SQLにはいろいろな種類がありますが、今回はBigQueryで使用するSQLについて解説します。
- テーブル形式のデータから特定の列や行を取り出す
- 取り出してきたデータを集計する
- テーブル形式のデータから特定の列や行のデータを書き換える
- 他のテーブルデータと組み合わせてデータを取り出す・集計をする
たとえば以下の図のような命令を出し、命令通りのデータを出したいときに書くSQLクエリの例は以下の通りです(わかりやすく簡略化した説明用のSQLクエリを例として挙げています。実際のデータベースで使用するSQLクエリとは少し違う可能性があります)。
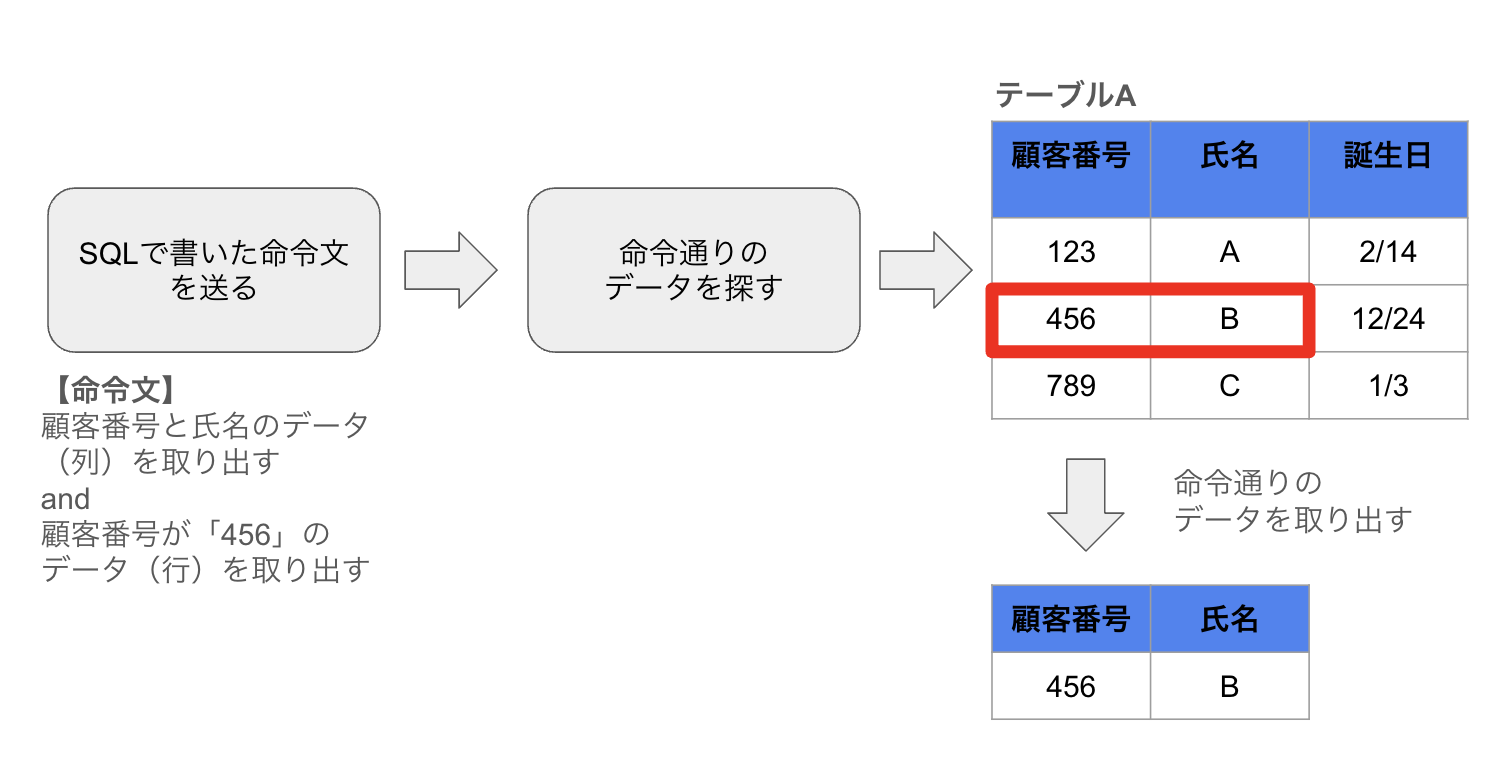
| SELECT | 顧客番号,氏名 | 取り出す列を指定する |
|---|---|---|
| FROM | テーブルA | データを取り出してくるテーブルを指定する |
| WHERE | 顧客番号=456 | 取り出す行を指定する |
もっと詳しくSQLについて学びたいという方は、書籍や動画などのSQL学習教材を使ってぜひ学習してみてください!
GA4のデータ構造とよく使うクエリを知ろう
それではさっそく、GA4のデータを使ってSQLクエリを書くときはどうするのか見ていきましょう。今回はGoogleが提供しているGA4のサンプルデータセットを用いて説明していきます。
GA4のデータ構造について
SQLクエリを書く上で、データを取り出す元になるデータテーブルの構造や入っているデータを理解することはとても重要です。このデータ構造を理解していないと、どんなSQLクエリを書けばいいかわからなくなってしまいます。そのため、今回はSQLを用いてGA4のデータを扱う上で、特につまずきやすいGA4データ構造の特徴を3つ説明していきます。
参照元[GA4] BigQuery Export スキーマ - アナリティクス ヘルプ
データの特徴(1):GA4のデータはネスト(入れ子)の構造になっている
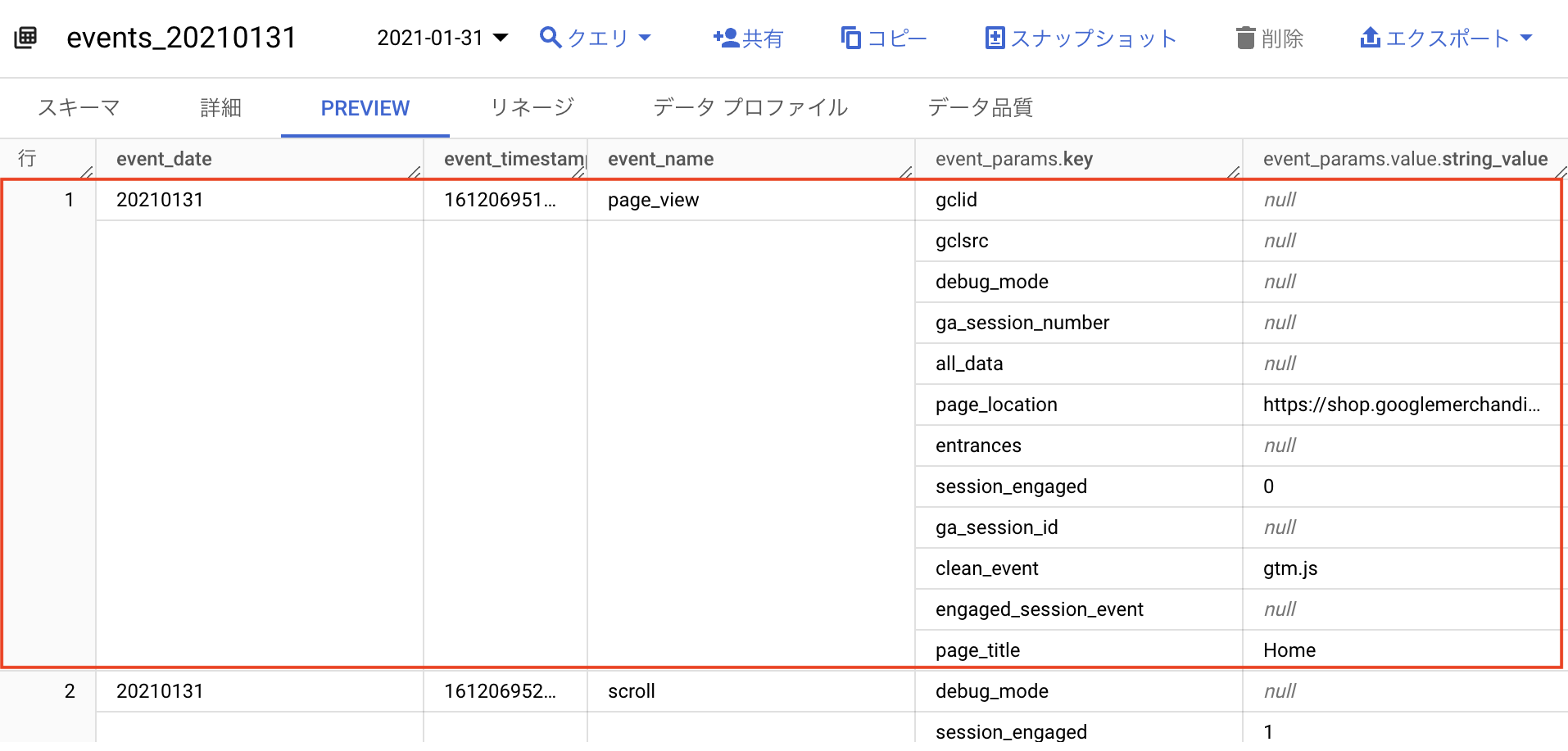
GA4のデータは、1行のなかに複数行が入っているというネスト(入れ子)形式でデータが構成されています。
下記の画像の場合、「page_view」というイベントで1行のデータが形成されていますが、その1行のなかにさまざまなイベントパラメータのデータがネスト(入れ子)形式で複数行入っています。
このように、GA4のデータは1行のなかに複数行入っているというネスト(入れ子)形式でデータが構成されているため、SQLでGA4のイベントパラメータのデータを扱う際にはネスト(入れ子)を解除する作業が必要になってきます。
unnest関数の使い方
unnest関数を使用することで、1行に複数行が入っている構造を解消し、SQLクエリで扱えるようにします。
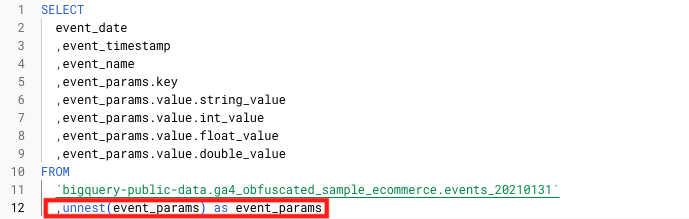
unnest関数によって、以下のようにネスト(入れ子)構造が解消されて、イベントパラメータも1行ずつで構成されるようになります。
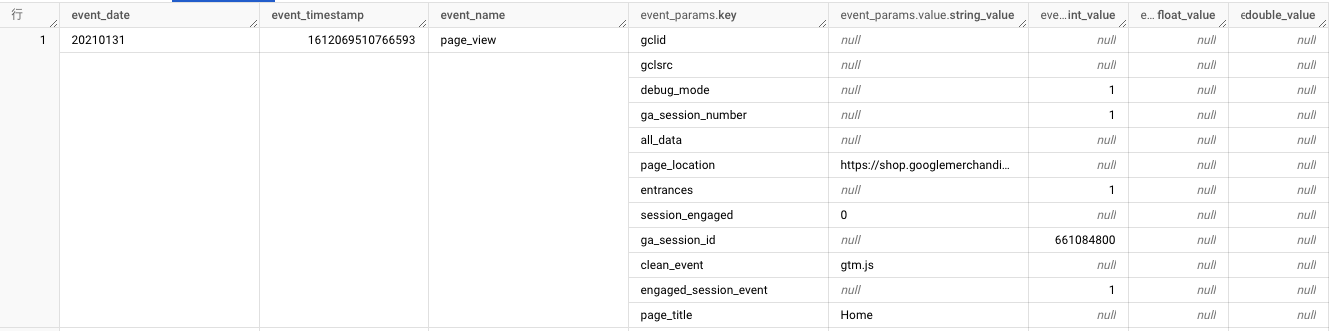
↓
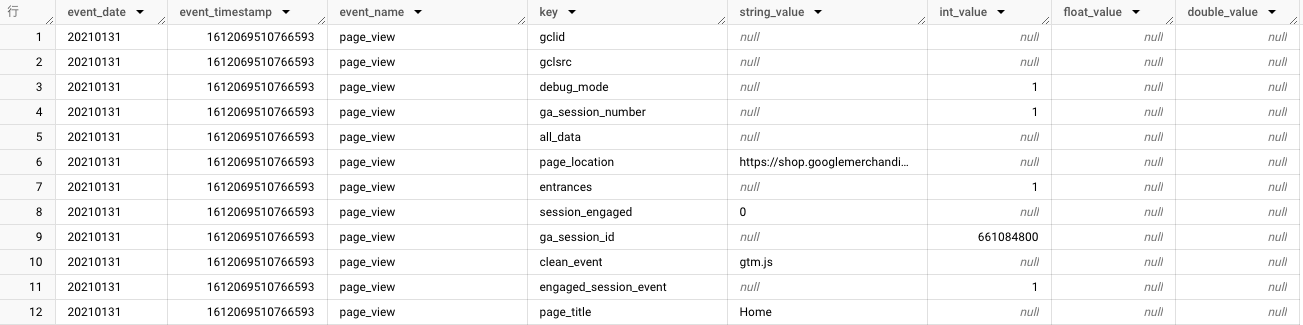
実際にGA4のデータをクエリで抽出する場合は、取り出したいイベントパラメータの値にあわせて、SELECT文内で「unnest関数」を使用することもあります。
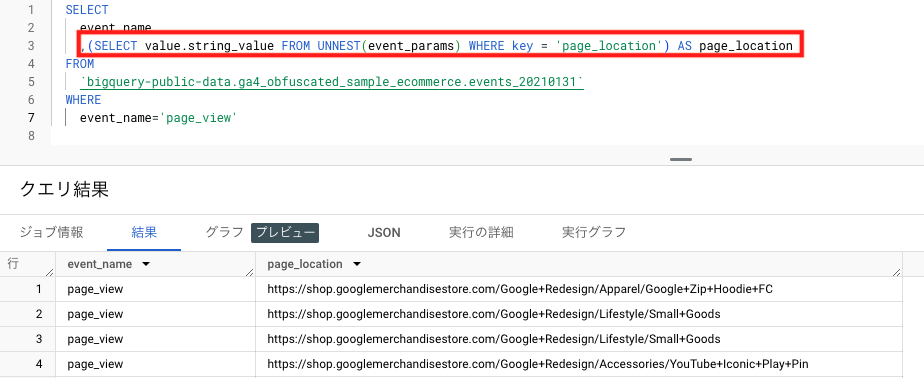
また、イベントパラメータの種類はkeyで区別し、それぞれのkeyに対して「STRING型(文字列型)」「INTEGER型(数字型)」などさまざまなデータ型ごとに列をわけて値が入っています。
例)
「page_location」というkey(パラメータ)に対して、「STRING型(文字列型)」の列にページURLの値が入っています。
例)
「ga_session_id」というkey(パラメータ)に対して、「INTEGER型(数字型)」の列にidの値が入っています。
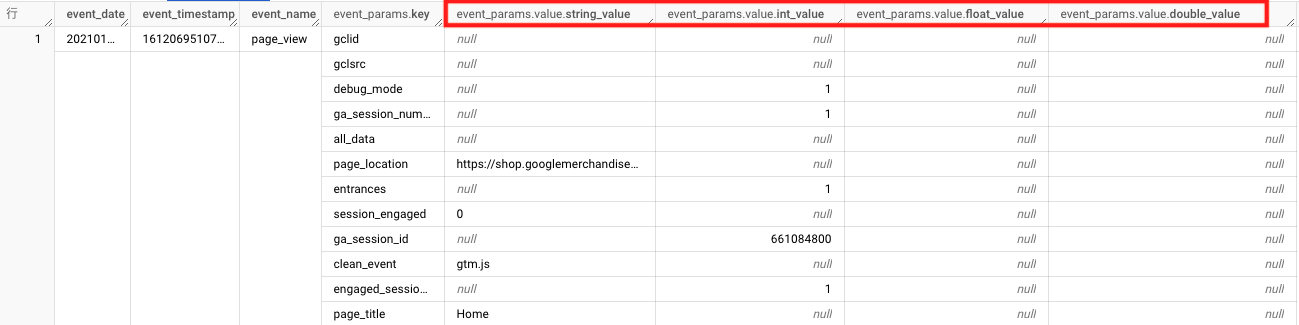
どのデータ型のイベントパラメータを取り出してくるかは、下記の部分を書き換えて指定します。

データの特徴(2):GA4のデータはevent_dateの日付ごとにテーブルが作成されている
GA4からエクスポートされたアクセスログのデータは、BigQuery上でevent_dateの日付ごとに分けてテーブルが作成されます。複数の日付にわたるデータを対象として扱いたい場合は、複数のテーブルを指定してSQLクエリを実行する必要があります。
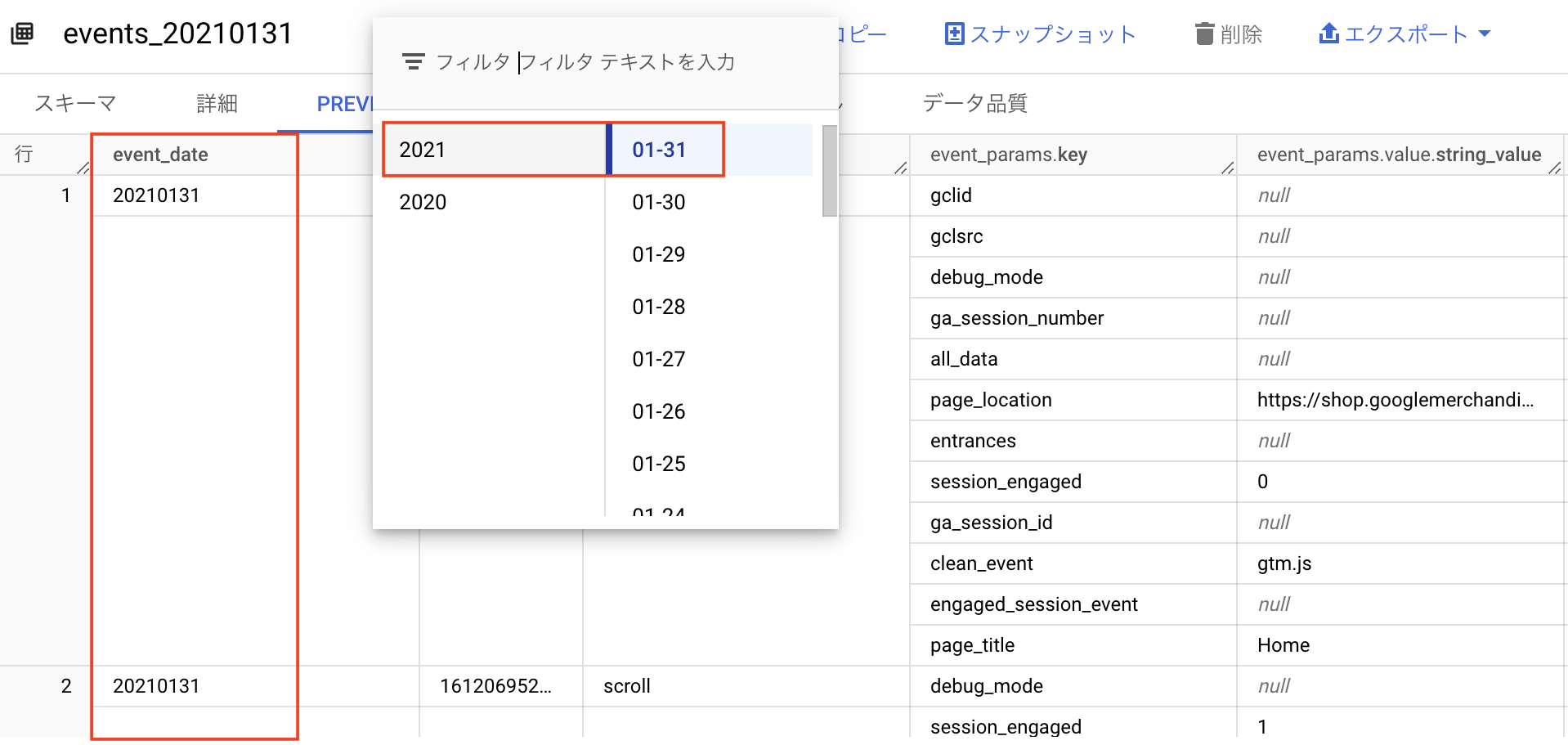
ワイルドカードテーブルと_TABLE_SUFFIXの使い方
FROM句で指定するテーブルに「*」を使用してワイルドカード形式(特定の日を指定しない形式)に変更し、WHERE句で_TABLE_SUFFIXを使用して、対象にするテーブルの最初と最後の日付を指定して複数のテーブルを対象とします。
参照元ワイルドカード テーブルを使用した複数テーブルに対するクエリ | BigQuery | Google Cloud
データの特徴(3):イベントが発生した日・時間を記録している「event_date」や「event_timestamp」は日付や時間の形のデータ型ではない
イベント発生日時を記録するデータについて
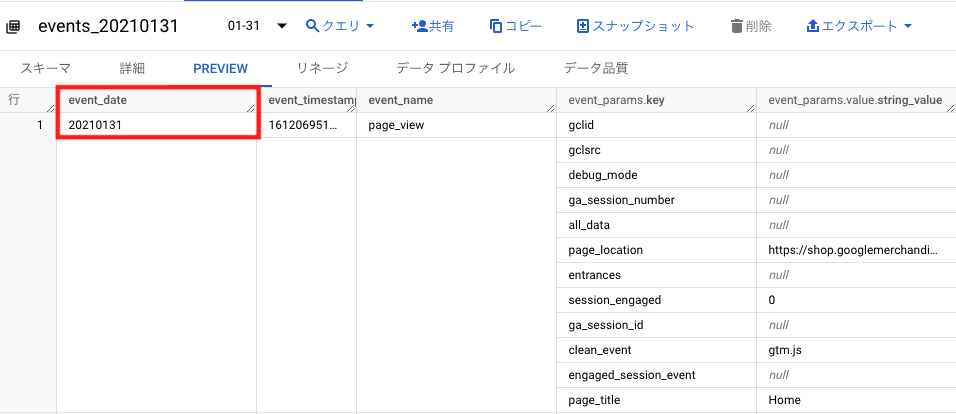
event_dateは、BigQueryのPREVIEW画面で確認すると、“20210131”という形で表示されています。これは日付型(DATE型)ではなく文字列型(STRING型)でイベントが発生した日を記録しているということです。
そのため、event_dateに記録されている日付のデータを、日付型(DATE型)で扱いたい場合には、日付型(DATE型)に変換するSQLクエリを書く必要があります。
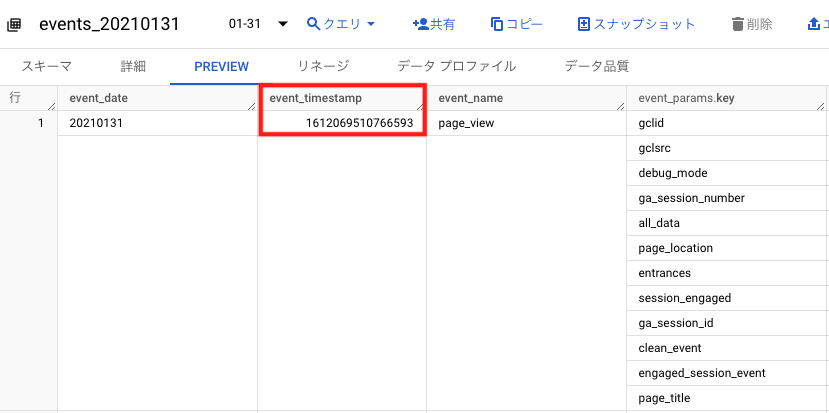
またevent_timestampは、BigQueryのPREVIEW画面で確認すると、“1612069510766593”という形で表示されています。これは数字型(INTEGER型)でイベントが発生した日時を記録しているということです。
そのため、event_timestampに記録されている日時のデータを、日時の表示形式で扱いたい場合には、日時の表示形式に変換するSQLクエリを書く必要があります。
日付・日時のデータ型・表示形式に変える方法
日付型のデータに変えたり、日時の表示形式に変更したりする方法はいくつかありますが、今回は代表的な例を解説します。GA4のデータを抽出する目的に合わせて使い分けましょう。
event_dateを日付型のデータに変える際は、「PARSE_DATE関数」を使用します。
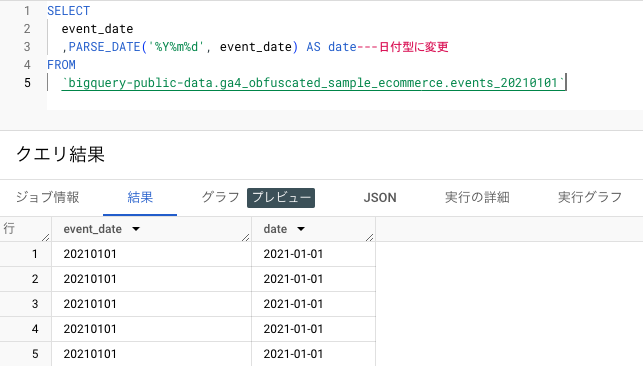
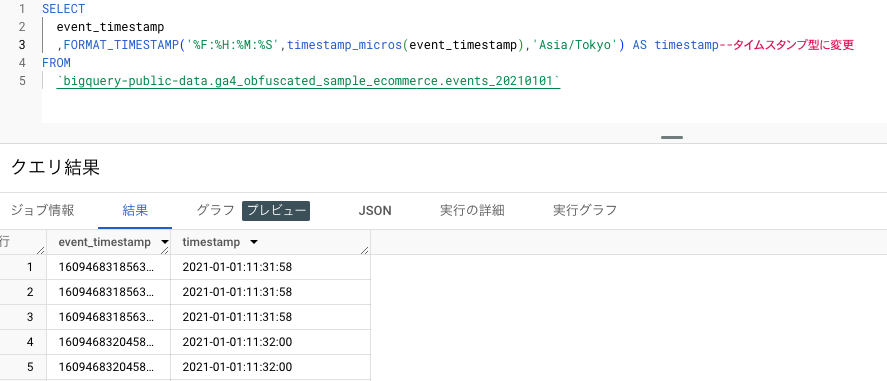
event_timestampを日時形式の表示に変える際は、「TIMESTAMP_MICROS関数」を使用してタイムゾーンを指定し、「FORMAT_TIMESTAMP関数」で日時形式の表示にデータを変換します。
「FORMAT_TIMESTAMP関数」を使用して日時形式の表示にデータを変換した場合、データ型はタイムスタンプ型ではなく文字列型(STRING型)となります。
参照元Timestamp functions | BigQuery | Google Cloud
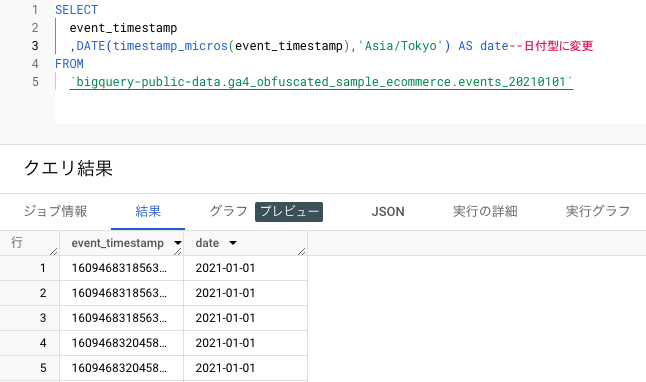
「DATE関数」を使用して、event_timestampからタイムゾーンを指定して日付データを取得することも可能です。
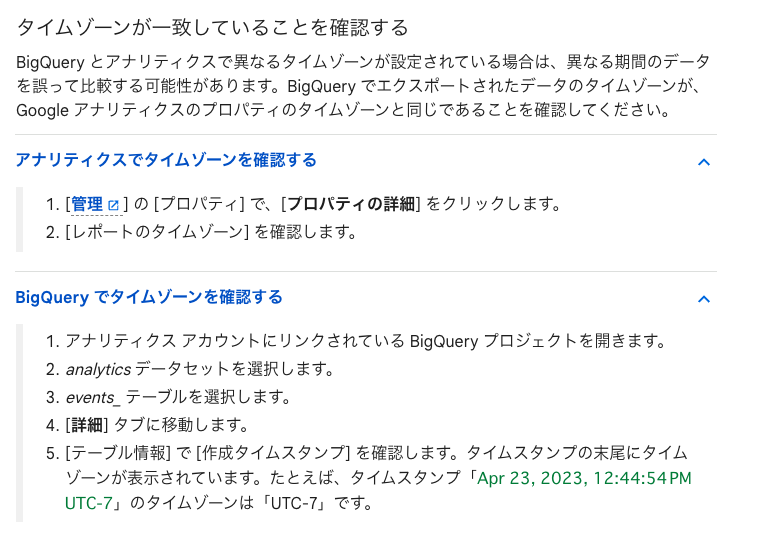
【補足】
GA4とBigQueryでタイムゾーンが一致していることを確認しましょう。
タイムゾーンが一致していない場合は、抽出・集計に使用したいタイムゾーンを指定するクエリを忘れないようにしましょう。
参照元[GA4] アナリティクス レポートと BigQuery にエクスポートされたデータを比較する - アナリティクス ヘルプ
よく使うクエリ
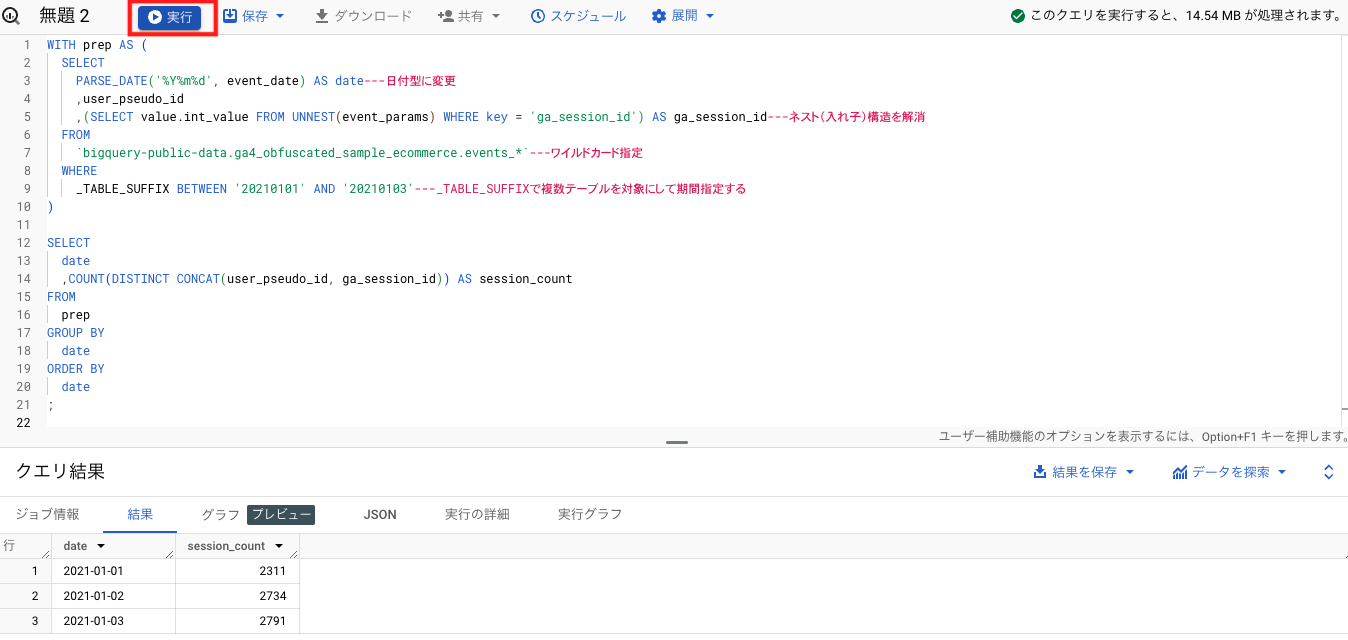
今回は、2021年1月1日から2021年1月3日のセッション数を出すクエリを例として、上記で説明した3つのデータ構造の特徴に対応するクエリを解説します。
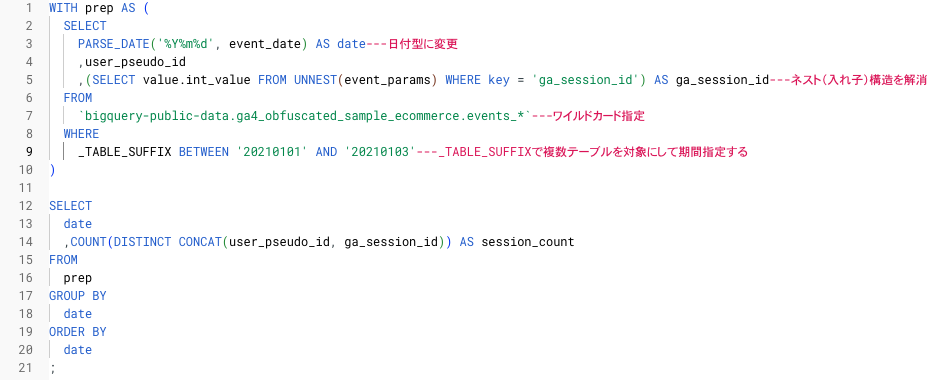
WITH prep AS (
SELECT
PARSE_DATE('%Y%m%d', event_date) AS date ---日付型に変更
,user_pseudo_id
,(SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS ga_session_id ---ネスト(入れ子)構造を解消
FROM
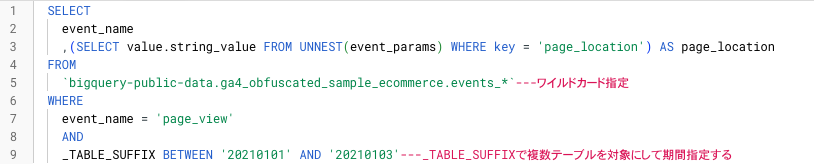
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*` ---ワイルドカード指定
WHERE
_TABLE_SUFFIX BETWEEN '20210101' AND '20210103'---_TABLE_SUFFIXで複数テーブルを対象にして期間指定する
)
SELECT
date
,COUNT(DISTINCT CONCAT(user_pseudo_id, ga_session_id)) AS session_count
FROM
prep
GROUP BY
date
ORDER BY
date
;
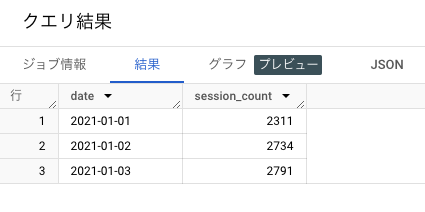
【補足:WITH句について】
今回は「WITH句」という、サブクエリ(SQLのなかにSQLを書くこと)に名前をつけて一時的に管理する機能を使ってクエリを書いています。
with句でprepと名前をつけて「日付型に変換して取り出したevent_date、user_pseudo_id、ネスト構造を解消して取り出したga_session_idのリスト」を作り、そこから日付とセッション数(user_pseudo_idとga_session_idを連結した値を重複を除いてカウント)を集計するという方法を使って、日次のセッション数を集計しています。
【補足:セッション数のカウント方法について】
GA4のセッション数の算出方法については公式ヘルプで以下のように定義されています。
- セッション数の算出方法
アナリティクスでは、ユニーク セッション ID の数を推定することで、サイトまたはアプリで発生したセッションの数を算出します。
この算出方法を再現するために、「user_pseudo_id」と「ga_session_id」という値を連結してユニークセッションIDを作り、そのユニークセッションIDの重複を除いてカウントし、セッション数を算出するという方法をとっていきます。
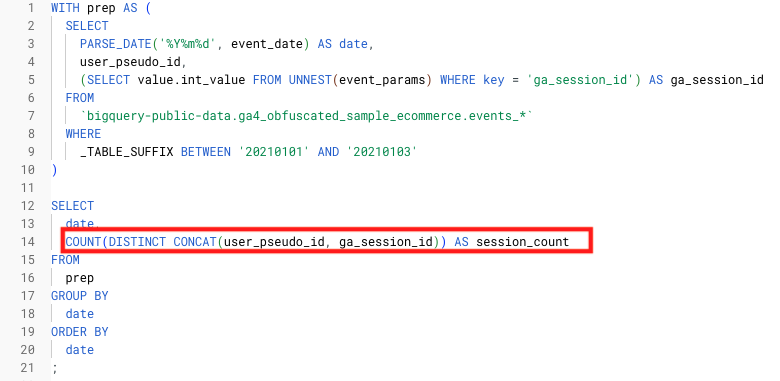
- CONCAT関数
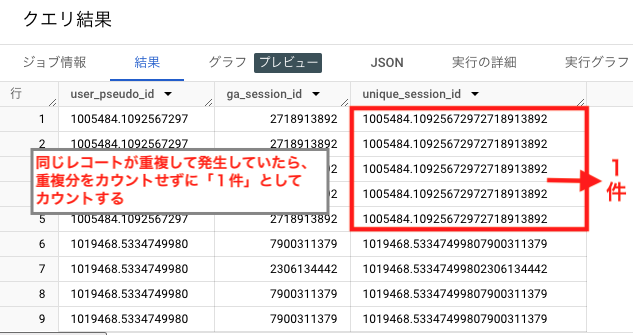
user_pseudo_idとga_session_idを連結してユニークセッションIDを作成する際に使用します。実際にuser_pseudo_idとga_session_idと、CONCAT関数を使用して連結して作成したunique_session_idを並べて確認すると、user_pseudo_idとga_session_idが連結されていることがわかります。
- COUNT DISTINCT関数
user_pseudo_idとga_session_idを連結して作成したユニークセッションIDの重複を除いてカウントする際に使用します。


BigQueryを使ってGA4のデータを扱う練習をしよう
最後に、BigQueryでGA4のサンプルデータセットを使ってSQLクエリを書く練習をする手順を解説します。
BigQueryのサンドボックスについて
本来BigQueryは従量課金制ですが、練習などでBigQueryを無料で使いたい場合は「サンドボックス」の使用をおすすめします。上限や制限があるので詳しくは「BigQueryサンドボックスを使用する」という公式ヘルプのページも併せてご確認ください。
参照元BigQuery サンドボックスを使用する - Google ドキュメント エディタ ヘルプ
また、サンドボックスを使い始める手順については、「BigQueryサンドボックスを有効にする」という公式ページで案内があるので、こちらを元に利用を開始してください。
参照元:BigQuery サンドボックスを有効にする | Google Cloud
GA4のサンプルデータセットを使う手順
BigQueryのサンドボックスの設定を終えたら、GA4のサンプルデータセットを使ってクエリを書いてみましょう。サンプルデータセットを使用する際は、サンプルデータセットについての公式ヘルプページにあるリンクをクリックしてください。
リンクをクリックすると、BigQueryが開いて、GA4のサンプルデータセットが表示されます。
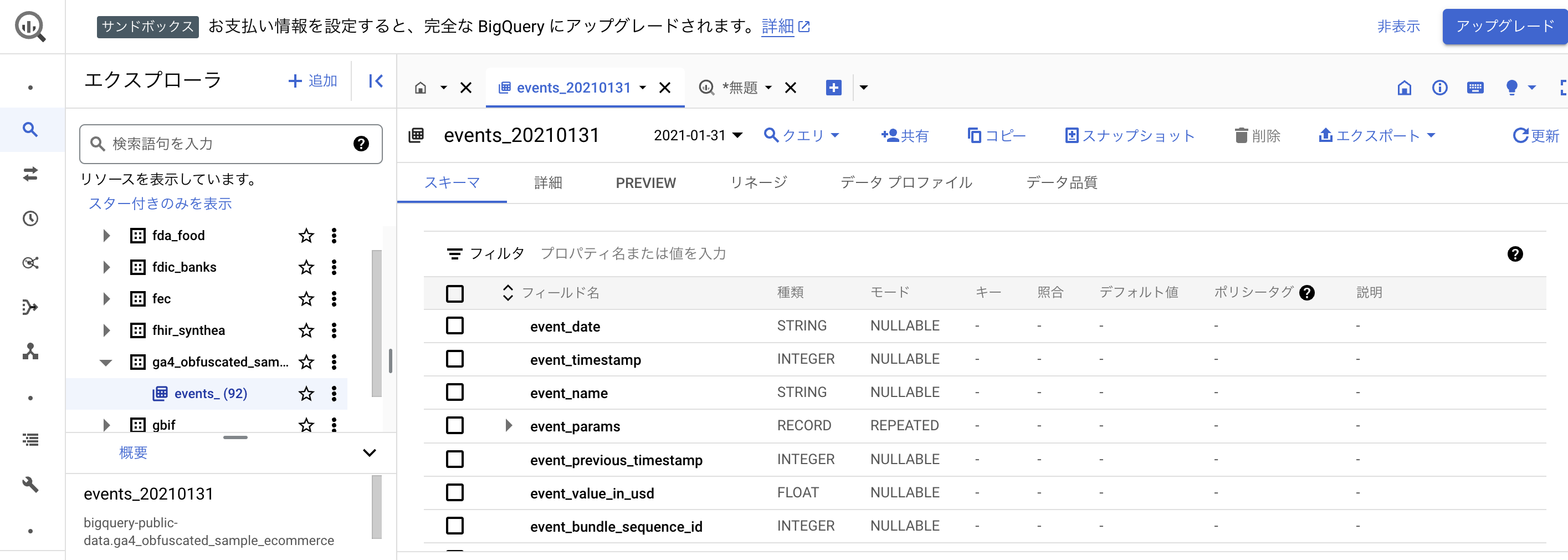
「クエリ」のボタンを押して「新しいタブ」をクリックしてください。
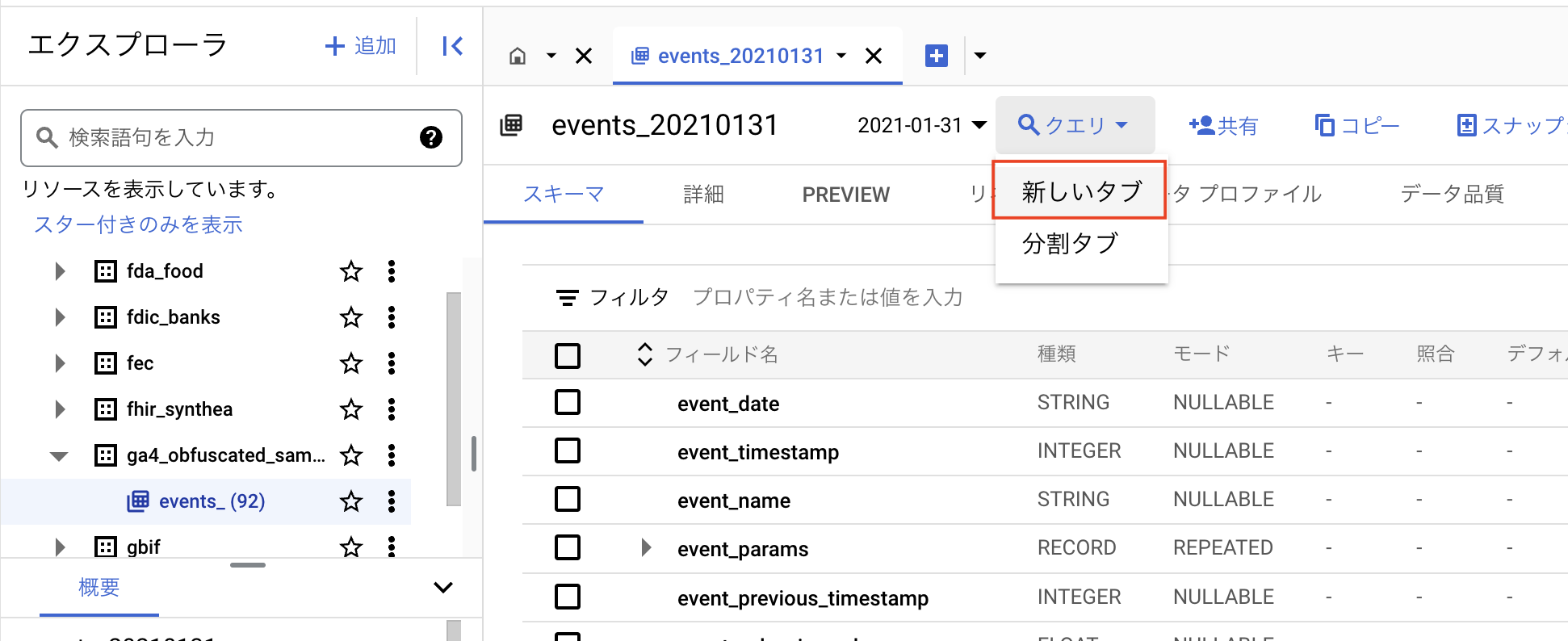
使用するデータセット名がFROM句に入った状態で、SQLクエリを書く画面が表示されます。
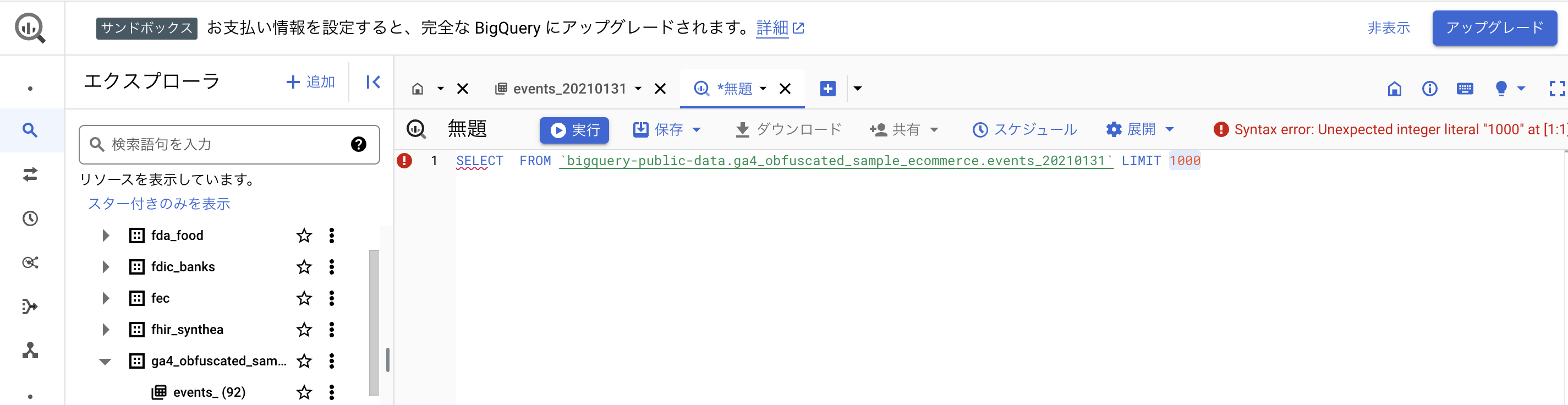
SQLクエリを書いて「実行」のボタンを押すと、SQLクエリが実行されて結果が下側に表示されます
もし、右上に赤字で何か文章が表示されている場合は、エラーが起きているので、エラーを解消してクエリを実行しましょう。

エラーを解消し実行できるクエリになると、緑のチェックマークが出てきて、処理されるデータ量も併せて表示されます。

最後に
GA4は無料版でもBigQueryへアクセスログのデータがエクスポートできるようになり、SQLを用いてGA4のデータを扱うハードルが下がりました。
SQLを用いてGA4のデータを出すうえで重要なことは、自分でSQLを書いてデータを出す=出すデータの定義を明確にして出すということであり、そのためにはGA4が取得して蓄積しているデータ構造を知ることが必要になってきます。
実際に自分でSQLクエリを書いてGA4のデータを扱ってみることで、「GA4はこうやってデータを集計していたのか」という気付きにつながり、GA4の仕組みをより理解することにつながります。GA4は使いづらい・よくわからないというお声も多いですが、そんなときこそGA4のデータをBigQueryで扱う練習をして、GA4のデータ集計の仕組みに触れてみてください。
学習コストはかかりますが、GA4を理解するために、「BigQueryを使ってSQLクエリを書いてデータを出してみる」という作業を一度やってみることはとても有効です。ぜひこの記事を参考にトライしてみてください。
※このコンテンツはWebサイト「Web担当者Forum - 企業Webサイトとマーケティングの実践情報サイト - SEO・アクセス解析・SNS・UX・CMSなど」で公開されている記事のフィードに含まれているものです。
オリジナル記事:GA4のデータをBigQuery&SQLで分析するときのポイント3選! データ構造とよく使うクエリを知ろう | GA4最前線コラム
Copyright (C) IMPRESS CORPORATION, an Impress Group company. All rights reserved.
ウェブ解析士協会のGA4講座のお知らせ
一般社団法人ウェブ解析士協会ではウェブ解析の初心者でもわかりやすい「Googleアナリティクス4講座」を開講しています。約3時間の講座でハンズオンでGA4を学ぶことができます。Googleアナリティクス4の導入からレポーティングまでを網羅した講座となります。GA4をいちから学んでみたい、体系的に学んでみたいという方はぜひお申し込みください。

