
この記事は、前後編の2回に分けてお届けしている。後編となる今回は、グーグルの内部文書を基に、Navboostクエリについてもう少し深く掘り下げたうえで、SEOにおけるブランド検索の価値について考えてみよう。
Navboostクエリとは何か
米政府とグーグルの訴訟で2023年に提出された証拠資料では、仕組みとしてのNavboostに関する情報が少し得られた。具体的には、クリック数を利用して検索順位を最適化している仕組みであることがわかったのだ。
グーグルは常にその存在を否定していたが、Navboostの考え方は非常に興味深いものであり、今回の流出文書でも、Navboostの仕組みとそれがどう使われているかについて、さらにもう少し詳しく知ることができた。ただし、この記事で取り上げたいのは「Navboostクエリ」という、それより狭い概念だ。
流出文書から、いくつかの例とコンテキストを見てみよう。
※Web担編注 以下の4項目は、グーグルからの流出文書の一部を参照しながら解説している。
流出文書はGoogle検索自体に関するものではなく、その関連システムの機能の使い方を示すもので、形式としては開発者向けのドキュメントだった。そのため、以下の各項目では開発者向けのドキュメントの情報を示している。
解説は開発者でなくても理解できるものではあるが、理解しづらい場合でも気にせずに読み進んでほしい。
ラディッシュ機能

ラディッシュサラダの話ではない。このモジュールは、他のセクションのようにあからさまに衝撃的な要素もなく、当たり障りがないように見えるが、今回流出した中で僕のお気に入りかもしれない。
強調スニペット(その別名が「RadishFeatures」か?)に関連しているらしく、Navboostクエリに関する興味深い言及がいくつもある。ここにある記載のほとんどは、強調スニペットとNavboostクエリの一対比較に関連しているように見える。つまり、「この質問に対して、これは優れた回答か?」と聞いているのだ。以下の項目は特に示唆に富む。
similarityScore (type: number(), default: nil)- Similarity score between this navboost_query and the incoming query.
「このnavboost_queryと受け取ったクエリの類似性スコア」
グーグルは、Navboostクエリに対する強調スニペットの可能性を評価しておいて、別の類似のクエリに対する検索でそれを表示しているのだろうか。
僕から見ると、これは限られた数のNavboostクエリ一覧を意味するもので、2018年に僕が仮説を立てていたあらゆる理由から、完全に理にかなっている。他に言及している箇所もこの理解に沿っているが、もう少し他のモジュールも見てみよう。
サブセグメント

このセクションはおそらく、ウェブページ内のセクションや文章をインデックス化することで、SERPから記事にディープリンクを張れるようにすることに関連していると思う(たとえば、英語版Mozブログ記事では左側に見出しのアンカーリンクが表示されるが、グーグル検索に表示される1行のサイトリンクからインプレッションを得ることも多い)。
これも、それ自体がどれも非常に興味深いのだが、この記事で関連があるのは以下の部分だ:
(e.g. a document might have multiple anchors or navboost queries).
「例:ドキュメントには複数のアンカーやNavboostクエリが含まれている可能性がある場合」imageQueryIndex (type: GoogleApi.ContentWarehouse.V1.Model.RepositoryWebrefImageQueryIndices.t, default: nil)- Pointer to the exact set of image navboost queries in the cdoc.
「cdoc内の一致する画像Navboostクエリセットへのポインタ」
もちろん、あるページが複数のクエリに対して表示される可能性があるのは当然だと思うかもしれない。グーグルの検索エンジニアらもこのことは十分承知しているのではないかと思う。
ではなぜ、「複数のセクションを含むドキュメントが複数のNavboostクエリに対して関連している可能性がある」ことを明示的に宣言する必要があるのだろうか。これを理解するのに最善の方法は、Navboostクエリが必然的に比較的異なる概念に関連している場合だ。似たようなものをあえて2つ用意する必要はない。シノニムやスペルミスなどは、上記の強調スニペットの例のように、最も類似するNavboostクエリでグループ化できる。
これも、まるで明確なクエリ(狭い意図?)のリストをデータとして持っているように見える。
研究科学検索のNavboostクエリ情報

このモジュールのやや重苦しいタイトルは、それが研究目的のためにあることを示唆しているように見える。具体的にどう使われるのかは不明だ。
説明を見ると、このモジュールは「データセットsource_urlに対する1件のNavboostクエリを表す情報」だという。つまり、これは検索クエリとそのクエリに対して表示されるページという特定の組み合わせに関連する情報のようだ。
この文脈での「tuple」(組)とは、この組み合わせのことだと思われる。そのため、特定のNavboostクエリに対する特定のページのインプレッションとロングクリック※を見ることになる。
ここから読み取れるのは、「特定のクエリに対して、あるページのクリック率が高ければ、それに応じて検索順位も調整されるはずだ」ということだ。
ただし、これは研究目的だとの説明があることに注意しよう。僕たちは何年も前から、ライブフィードバックループを示すテストが実際に現場で(たとえば、ランド・フィッシュキンによって)行われるのを目にしてきたが、ここに書かれているのは、それとは少し違うかもしれない。代わりに、そのようなデータに基づいてアルゴリズムの他の部分に情報を提供することが目的なのかもしれない。
確かなのは、グーグルがページに対するクエリ固有のエンゲージメントについて、こうした明確な言葉で理路整然と考えているということだ。この場合も、それが可能なのはヘッドキーワード※か、または大量のグループ化された類似のキーワードだけだ。
画像一致ブーストNav(boost?)クエリ

これが画像検索に関連しているのは明らかだが、それでも極めて示唆に富んでおり、画像検索と(一般に、より収益性の高い)ウェブ検索には、グーグル内部の検索エンジニアリングに関する専門用語の使用においては確実に、多くの共通点があると考えられる。
ここでも、次の記載がある点が興味深い:
confidence (type: integer(), default: nil)- Associated confidence scores for the image for the query.
「クエリに対する画像の関連信頼スコア」imageClickRank (type: integer(), default: nil)- Click-based rank of the image for this query.
「このクエリに対する画像のクリックベースの検索順位」
こうした「クリックベースの検索順位」を、画像に関して実現する(特に、検索の膨大なロングテール全体で実現する)方法は、次の2つしかない:
- ボリュームの多いキーワードに対してのみ行う
- ボリュームの少ないすべてのキーワードを、最も近いボリュームの多いキーワードに融合させる
どちらのケースも考えられるし、今日の僕たちにも同じような影響がある。次に、この点について考えてみよう。
グーグル流出文書の内容が意味すること
前のセクションで、かなり技術的・学術的な話だと思われたとしても無理はない。ある程度はその通りだし、それも悪いことではない。言葉の意味を理解することは、ここで思いがけずに得られた情報をより活用するための重要な第一歩だと思う。
ただし、特に「ヘッドキーワード」に対する検索順位に関連して、注目してほしい戦術的な意味合いが2つある:
クリックベースの検索順位システムが示唆する、「UX」「ブランド」「クリックのしやすさ」を優先させるという一般的な要件。
ボリュームの多い検索キーワードと一対一の関係にあるページの特定。
①については、僕を含む多くの人が何年も前から、さまざまな場所で繰り返し詳細に論じていることなので、ここでは取り上げない。
②の方がはるかに興味深いと思う。
SEO専門家のマイク・キング氏は、今回の流出文書に関する同氏の最初のまとめ記事で、非常に洞察力の鋭いことに、パンダアップデートに関連する次の2012年の特許とのつながりを指摘した:
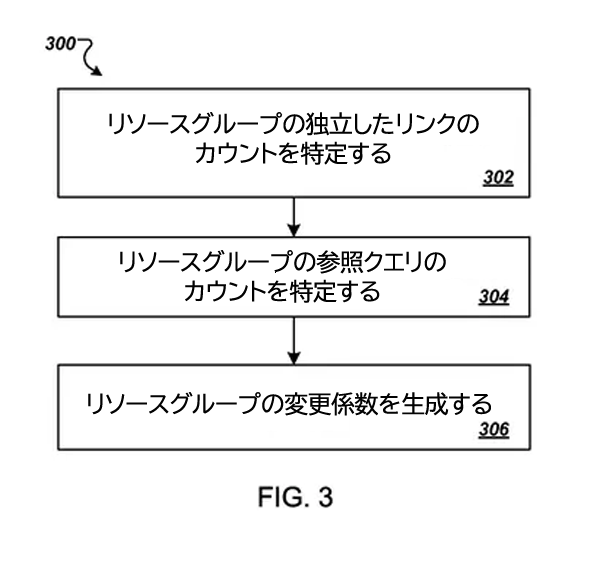
このプロセスは、「ブランド検索のボリュームを考慮したうえで、ページのリンクが疑わしいほど多すぎたり少なすぎたりするか」、言い換えれば「過剰なSEOであるかどうか」を調査することと解釈できるかもしれない。
上のスクリーンショットの真ん中にある文章は、今日の僕たちにとって興味深い:
リソースグループの参照クエリのカウントを特定する
特許文書では、上図の2つ後には、以下の非常に素晴らしいフローチャートが記載されている:
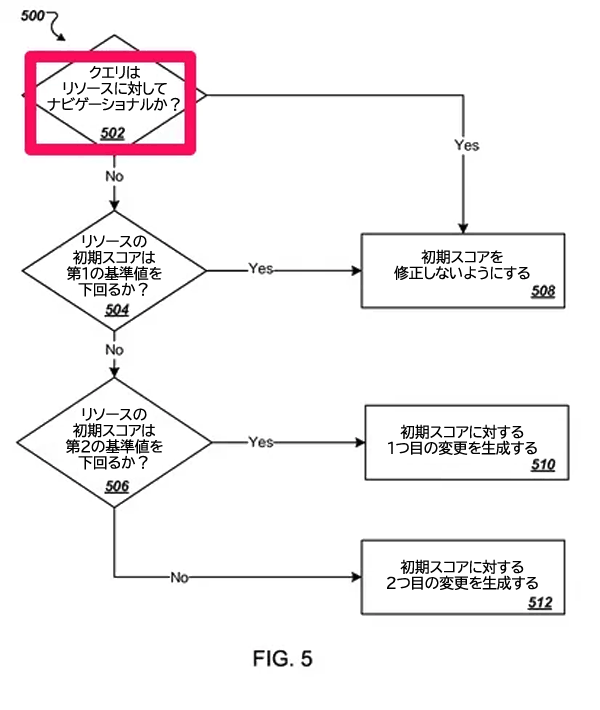
「リソースに対してナビゲーショナルな参照クエリかどうか」を、どうすれば判断できるのだろうか? そこで必要になるのが、このNavboostという仕組みだ。
ブランド検索の二重の利点
ブランド検索は、SEOにおいて価値が高い。多くのサイトリンクによって潜在的な競合他社が目立たなくなりウェブサイトへのトラフィックを促進できるだけでなく、非ブランド検索に情報を提供するアルゴリズムに組み込める可能性もある。少なくとも、よりボリュームの多いキーワード(と概念?)をめぐって上位で競争するようになったらそうなるだろう。
そしてブランド検索は、「特定のキーワードや概念に対するクリック数において、単に1件のページやサイトが他を圧倒すること」と定義できるかもしれない。
僕がこの記事の冒頭で、「誰もが想像するよりはるかに単純に見える」と指摘した根拠はこの点にある。
また、ここで重要なのは、この定義によるブランド検索が必ずしも「Microsoft」のようなブランドだけではないということだ。間違いなく自分が明白な選択肢である任意のキーワードがこれに該当し、(マイクロソフトにとっては)「Windows」のようなキーワードが好例だ。
同僚のドクター・ピートは、たとえばOpenAIや自動車ブランドなど、この考え方について業界レベルで考察して多くの記事を書いている。
これで察しがついたかもしれないが、これはまさに、MozがBrand Authorityのツールを構築した背景にある考え方でもある。
ブランドオーソリティの活用
言うまでもなく、ここでの最大の収穫は、君もすでに知っていた事実だろう。それはSEO担当者が、ブランドを今なお軽視しているということだ。検索順位決定要因として、SEO戦略として、そして指標としても、軽視してしまっている。
AIに汚染されたSERPや最近のヘルプフルコンテンツアップデート(HCU)およびコアアップデートを考えると、むしろグーグルはブランドをさらに重視しているように見える。
多くのSEO担当者は、ブランドがなくてもオーガニック検索で大きな成果を収められた時代を懐かしんでいるが、残念ながら、この兆候はかなり以前からあったと思う。
※このコンテンツはWebサイト「Web担当者Forum - 企業Webサイトとマーケティングの実践情報サイト - SEO・アクセス解析・SNS・UX・CMSなど」で公開されている記事のフィードに含まれているものです。
オリジナル記事:Navboostクエリとは何か? グーグル流出文書からみえたSEOにおける意味と対策【後編】 | Moz - SEOとインバウンドマーケティングの実践情報
Copyright (C) IMPRESS CORPORATION, an Impress Group company. All rights reserved.

