

今週のピックアップは2記事。SEO業界の達人である住氏と渡辺氏による、「検索意図」「高品質なコンテンツの定義」の情報をお届けする。「検索意図? それぐらい知ってるよ」というあなたこそ、ぜひ読んでほしい良記事と、「なるほど、高品質なコンテンツの正しい考え方はこうか」とわかる良ツイートだ。
今週はほかにも、あなたのSEO力に役立つ情報が多い。
グーグル主催イベント「Search Central Live Tokyo」関連のツイートは全46件紹介、さらにE-E-A-T、動画SEO、Search Consoleの一括エクスポートでの費用節約術などなど、盛りだくさんだ。
最後に紹介している「デジタル庁のサイト」の件も、実はサイトづくりに役立つ非常に高質な情報を無料で得られる、お得ネタだ。ぜひ確認してほしい。
- SEO達人の「検索意図」解説で、あなたのSEOをレベルアップ
- SEO達人の「高品質なコンテンツの定義」解説で、あなたのSEOをレベルアップ
- グーグル検索で重要なE-E-A-Tを高める方法を教えます
- 参加した人にも参加できなかった人にも役立つ、Google Search Central Live Tokyoの有用ツイートまとめ
- ページの動画が認識されない「視認性」の問題をSearch Consoleが説明するように
- 「.store」ドメインのような新しいgTLDはグーグル検索で不利になるのか?
- 成人向けサイトではGooglebotの年齢を確認する必要なし
- noindexはインデックス制御、robots.txtはクロール制御
- Search Console一括データ エクスポートでびっくりな高額請求にならないための事前対策
- デジタル庁のサイトがちゃんと作られていて参考になるらしい
- Google、モバイル検索でPerspectivesフィルタを導入
- Google Bardがロケーション情報を取得し関連性がより高い回答を返すようになる
- 今週のピックアップ
- グーグル検索SEO情報①
- グーグル検索SEO情報②
- 「.store」ドメインのような新しいgTLDはグーグル検索で不利になるのか? ccTLDにするかgTLDにするかはターゲット国によって決める (Reddit) 海外情報
- 成人向けサイトではGooglebotの年齢を確認する必要なし 素通りさせてかまわない (グーグル検索におけるセーフサーチとは) 国内情報
- noindexはインデックス制御、robots.txtはクロール制御 役割を混同しない (John Mueller on Twitter) 海外情報
- Search Console一括データ エクスポートでびっくりな高額請求にならないための事前対策 効率的な4つの構成を提案 (グーグル 検索セントラル ブログ) 国内情報
- デジタル庁のサイトがちゃんと作られていて参考になるらしい 一見するとなんてことのないサイトだけれど (Qiita) 国内情報
- 海外SEO情報ブログの掲載記事からピックアップ
今週のピックアップ
SEO達人の「検索意図」解説で、あなたのSEOをレベルアップ 検索意図をさらに踏み込んで理解 (ボーディー) 国内情報
検索意図に関する詳細な解説を、ボーディーの住太陽氏が公開した。「検索意図? それぐらい知ってるよ」というあなたこそ、ぜひ読んでほしい良記事だ。
「検索意図」とは、住氏の言葉を借りれば、次のような定義だ:
検索意図とは、ユーザーが入力した検索クエリ(検索キーワード)について、その検索クエリを入力した理由、またはその背後にある目的のこと
検索意図にはいくつかの分類方法がある。それぞれの分類方法と、各分類に対応する検索意図の特徴を、グーグルや他の組織の論文やドキュメントなどをふまえ、具体例も挙げながら住氏は説明している。
しかし住氏は、こうした分類について「ユーザーの意図を推定してクエリを処理するという検索エンジンの運営側からの視点で分類されたもの
」であると注意を促している。
SEOを単に「検索エンジンからのトラフィックを増やす」ことではなく、「ユーザーが検索するタイミングをユーザーとの接点を作るチャンスだととらえる
」ものだとすると、検索意図をマーケティング観点と組み合わせて考える必要があるのだ。
その観点もふまえて住氏は、「検索意図の5タイプ」を次のように解説している:
インフォメーショナル・インテント – 何かを知るために情報を見つける意図。意味や定義、方法やコツなどを探す。あらゆる検索意図の中で最も回数が多い。この検索意図に応えることによって、マーケターは生活者との接点を作ることができる。
ナビゲーショナル・インテント – 特定のウェブサイトまたはウェブページに移動する意図。ユーザーの本来の目的は「移動先のサイトやページで何をするか」にあるため、ユーザーの意図としては意味が薄く、クエリを処理する検索エンジン側の視点での検索意図である。
トランザクショナル・インテント – 訪問したサイト上で注文や決済やダウンロードなど何らかの行動をする意図。トランザクショナル・クエリを入力するときにはすでに行動する気持ちが固まっていることが多い(参考:ZMOT)。
コマーシャル・インテント – 購買などの商取引のために調査する意図。商品やサービスの比較や、販売者の評判や信頼性を調べる。「コマーシャル調査インテント」とも。商品詳細ページやサービス詳細ページのほか「おすすめランキング」コンテンツも有効。
ローカル・インテント – 地理的な場所に関連する情報や事業者を探す意図。旅行先で訪れる場所を検討したり、現在地近くのカフェを探したり、自宅に出張してくれる工事業者やフードデリバリーを探す。ローカルビジネスにとって最重要の検索意図。
こうした分類を、「オンラインビジネス」「ローカルビジネス」などでマーケティングファネルの各段階と対応させながら住氏は解説してくれている。

また、これらの意図で検索をする瞬間を表す「マイクロモーメント」についても住氏は触れている。
ユーザーの検索意図に合致したコンテンツでないと上位表示は不可能だと言っていい。非常に丁寧な解説で確実に役立つので、ぜひとも全体を読んでほしい。
大事なことなので、最後にもう一度。「検索意図? それぐらい知ってるよ」というあなたこそ、改めて検索意図について深く考える良いチャンスだ。ぜひ元記事をしっかり読んでほしい。
- すべてのWeb担当者 必見!
SEO達人の「高品質なコンテンツの定義」解説で、あなたのSEOをレベルアップ Googleが定義するものではない (Takahiro Watanabe on ツイッター) 国内情報
「高品質なコンテンツってどんなもの?」「高品質の定義は?」と疑問に思い調べたことがある人に、ぜひ読んでほしい情報がある。
渡辺隆広氏がこんな見解をツイッターに投稿していた:
「高品質なコンテンツ」関連の質問も同じ。自分が携わる事業領域における”高品質”を定義しなければいけないわけで、それはGoogleに質問しても期待する答えは出てこないと思う。 自分の事業なんだから、その事業に知見がある人に相談したほうがきっと頭の中を整理できる。
— Takahiro Watanabe (@takahwata) June 16, 2023
SEOは「市場」「事業構造」「ユーザー」を分析することから始まる。みんなSEOだからとGoogleを相手に考えがちだけど、そうじゃない。
— Takahiro Watanabe (@takahwata) June 16, 2023
おそらく、Search Central Live TokyoイベントのQ&Aセッションで取り上げられた「高品質コンテンツ」に関する質問に対してだろうと思われる(Search Central Live Tokyoイベント関連の情報は、このページのもうちょっと下のほうでしっかり取り上げているので、そちらも見てほしい)。
「SEOだからグーグルが重要」と思っている人には違和感があるかもしれない。しかしこれは、至極まっとうな本筋の意見だ。
あらゆるタイプのコンテンツについて、グーグル(の社員)が高品質を定義できるはずがない。自社サイトのコンテンツについて品質が高いかどうかを自分たちで定義できないとしたら、それは専門性や経験、信頼性が足りていないということになる。つまり、品質が高いコンテンツを作るのは難しいのではないだろうか。そして、グーグルに答えを求めるのはお門違いといえる。
もちろんグーグルが重視しているE-E-A-Tなどの要因や、それを示す情報とその見せ方も大事ではある。それらをふまえたうえで、「こういったコンテキストのユーザーにとって、こういったコンテンツが価値があるはずだ」と判断できるドメイン知識と経験があってこその「高品質なコンテンツ」なのだ。
- すべてのWeb担当者 必見!
グーグル検索SEO情報①
グーグル検索で重要なE-E-A-Tを高める方法を教えます サイト外の活動も重要 (アユダンテ株式会社) 国内情報
近年のグーグル検索は、特にYMYL分野において高いE-E-A-Tを備えたコンテンツを優先する。では、E-E-A-Tを高めるにはどうすればいいのだろうか?
アユダンテのコガン・ポリーナ氏がセミナーで語った「E-E-A-Tの概要と具体的に何をやるべきなのか」を、同社の江沢真紀氏がブログ記事としてまとめている。
次のような施策を提案している。
サイトレベルでできること
- HTTPSなどユーザーのセキュリティを重視する
- ユーザーを騙すようなコンテンツを掲載しない
- 充実している会社情報
過去に得た表彰やメディアで取り上げられた際の情報などもあると良い - 構造化データマークアップを活用する
- お問い合わせ先の分かりやすい導線を設置
- ECはお支払い方法、郵送、返品などについての情報
- レビューや体験版を掲載
- UGCをしっかりモニタリングし、管理する
- 専門領域以外のコンテンツを増やしすぎない
ページ(記事)レベルでできること
- 高品質でオリジナルなコンテンツを作る
- 最新情報に更新する
- 文中で「経験」と「権威性」を具体的に表す
- 権威性・専門性・経験のある記者/チームに記事を書いてもらう
- 記者プロフィールで権威性と専門性を表す(別ページがあっても良い)
- 必要に応じて専門家に監修してもらい、監修者情報を明記する
- 引用元の情報を明記する (信頼性がある引用元を使用)
- アフィリエイトリンクがある場合は
rel="sponsored"属性と文章でも明記
また、サイトの外でE-E-A-Tを強化することも重要だとポリーナ氏は言う。実例として自分自身を挙げている。
今Googleで「コガン・ポリーナ」と検索すると、コガンさんのナレッジグラフの写真や本が出ますが、ここを作るためにも今日のようなセミナーに出たり本を書いたり、Twitterをやったり、SEOのサミットに行って専門家と交流したり、とにかく他者に理解してもらって評価してもらって、文章で残していく活動をしています。
どの分野でも自分を知ってもらわないとE-E-A-Tは作れません。
知ってもらって、評判になって、ネット上にその証拠を残してもらうことが必要なのです。
こう考えると、(自分のブログだけでなく)この連載コラムをWeb担で長年執筆してきたことは、筆者の(SEO分野での)E-E-A-T構築に貢献しているのかもしれない。
とにもかくにもE-E-A-Tを高めることにおおいにヒントになる内容だ。元記事で詳細を確認してほしい。
- SEOがんばってる人用(ふつうの人は気にしなくていい)
参加した人にも参加できなかった人にも役立つ、Google Search Central Live Tokyoの有用ツイートまとめ 数年ぶりの対面イベント (#SearchCentralLive on ツイッター) 国内情報
2023年6月16日に渋谷のグーグル本社にてSearch Central Live Tokyoが開催された。数年ぶりの対面イベントだ。参加者によるツイッターの投稿で役に立ちそうなものを集めた。
イベントではさまざまなトピックが語られたが、ここではツイートを次の6カテゴリに分けて紹介する:
※ぜんぶで46個のツイートを埋め込んでいるため、ツイート形式での表示に時間がかかるのはご容赦いただきたい
Google検索とAI
Google ゲイリーさん
— いながきですよ(サンクレイオ翼) (@IngkOsgt) June 16, 2023
あくまでコンテンツの品質。
AIが使われたか、どう制作されたかをGoogleは気にしていない。#SearchCentralLive
コンテンツとしてどうやって作られたか、ではなく
— woody (@og_webm) June 16, 2023
結果何が作られたかが大事#SearchCentralLive
[QA] #SearchCentralLive
— り (@ri7130) June 16, 2023
ユーザ体験は第一としても、実務として「AIを使った高品質なコンテンツ」を作るに、はどうしたらいいですか。
→アウトプットの品質が高ければ、その生成過程はAIでも構わない。最終的に人手のチェックが必要。LLMはそこまで達していない。必ず自分の目でレビュー・評価を。
最終的にコンテンツ品質が高ければAIを使っても関係ない。ただし、いまのAIはではそこまでたどり着いていない。 #SearchCentralLive
— yuta-yanagisawa (@YanagisawaYuta) June 16, 2023
Google ゲイリーさんから
— いながきですよ(サンクレイオ翼) (@IngkOsgt) June 16, 2023
高品質なコンテンツを作るには人によるレビューが重要。必ずAI生成コンテンツにもレビューが必要。
と、改めて人間によるレビューの重要性の話。#SearchCentralLive
コンテンツの生成方法じゃなくて、コンテンツの本質を評価するので、Googleの観点からはAI生成コンテンツに対してAI生成コンテンツであることを明記する必要はない by @methode#SearchCentralLive pic.twitter.com/gDa0f4PWwo
— Polina Kogan/コガン ポリーナ (@PolinaKogan) June 16, 2023
A:Googleは、コンテンツの有益性を第一にしているので、どう作られたかは気にしていない。監修が必要な場合など、ユーザー視点で「AIが作った」説明が必要なら、注釈を入れるべきだろう。
— 長谷川 翔一 / 編集とマーケティング (@haseshout) June 16, 2023
Google観点で「AI生成」を書くことには意味がない。
メタタグの導入も考えられるが、悪用されそうなので…。
Q:AIが体験者を装ったコンテンツを量産していくリスクへの対策は考えているのか?
— 長谷川 翔一 / 編集とマーケティング (@haseshout) June 16, 2023
Gary:イエス。Google社内では、現在AIに関するディスカッションは大量に進んでいる。難解な問題ばかりだが、結論が出たものはhttps://t.co/WdFMXdyw1dに掲載する。https://t.co/ZEMUhRERlu#SearchCentralLive
AI生成に関するガイドライン。https://t.co/U4DbIPCDsO
— 長谷川 翔一 / 編集とマーケティング (@haseshout) June 16, 2023
例えば、箸はご飯を食べるのに使えるし、人を突くのにも使えてしまいます。AIも同じです。使うこと自体は悪くないですし、自動化自体も悪くありません。使う目的がガイドラインに抵触しているかどうかが問題になります。#SearchCentralLive
AIを検索コンテンツに使うこと自体は問題ない。ランキング操作のために使うのはポリシー違反。
— ミエルカくん🐱 (@Mieruca_kun) June 16, 2023
もしそういうスパムコンテンツを見つけたら報告を#SearchCentralLive pic.twitter.com/pz8l3A8PQp
(Bardによる翻訳)
— り (@ri7130) June 16, 2023
機械学習ベースのランキングアルゴリズムとシグナルは、人間が人間のために作成したコンテンツでトレーニングされています。 それらは、自然なコンテンツをよりよく「理解」し、促進します。#SearchCentralLive
Gary:機械学習はGoogleで20年以上使われてきていた。最初は、スパム対策。いまは、さまざまなシーンで使っている。
— 長谷川 翔一 / 編集とマーケティング (@haseshout) June 16, 2023
例えば、GoogleレンズやGmail。最近、検索でも、クローリング・インデックス・サービシング・ランキングのすべてのシーンで使用している。
#SearchCentralLive pic.twitter.com/aLvHb1q6xu
・RankBrain
— ムラヤマ ユウスケ (@muraweb_net) June 16, 2023
ロングテールクエリに対してユーザーにとって良い結果を見つける。
・MUM
複雑なクエリ内の概念をより適切に結びつけることができる。
・Bert
クエリ内の単語の関係をより良く理解できる。#SearchCentralLive pic.twitter.com/JJJfF0BvjQ
LLMを使った生成においては、誤った情報を自信を持って正しいと言い切ることがあるし、現在のコンピューターサイエンスでは100%取り除くには難しい。
— Tanaka Hiroki (@hyroki1980) June 16, 2023
だから自分で真偽を確認できないとLLMを活用するのは難しい。
#SearchCentralLive pic.twitter.com/yInWn2veVK
先日のSMXでも何度も話題にあがってましたが、LLMはまだまだ幻覚(Hallucinations)が発生していて、素直に信頼して頼ってはいけない
— Polina Kogan/コガン ポリーナ (@PolinaKogan) June 16, 2023
Googleももちろんその改善に向かって力を入れていますが、LLMのアウトプットを必ずダブルチェックする必要があります#SearchCentralLive pic.twitter.com/O2m0862BXq
LLMを使って返ってきたものには間違った情報も含まれる可能性がある。少なくしたいけど0にするのは難しい。なので、返ってきたものをそのまま信用するのではなくチェックすること。#SearchCentralLive pic.twitter.com/V1s7C5TZRp
— ムラヤマ ユウスケ (@muraweb_net) June 16, 2023
動画SEO
動画コンテンツにはIndexとfetchがある。動画のある場所にcrawlしてIndexするだけだと、キーモーメンツと動画セグメントは利用できない。fetchされるとこれらの機能は利用できるようになる。#SearchCentralLive pic.twitter.com/4IgW9AM47o
— ムラヤマ ユウスケ (@muraweb_net) June 16, 2023
インデックス→動画があると理解される
— よーこ氏@JADE (@kasurinoyokosan) June 16, 2023
フェッチ→動画の中身が何なのか理解される
なるほど〜#SearchCentralLive pic.twitter.com/e6UP6wkVIs
動画コンテンツを検索結果に表示させるには
— ミエルカくん🐱 (@Mieruca_kun) June 16, 2023
通常検索、動画タブは通常のインデックスでOK
キーモーメントはフェッチが必要
(フェッチ: 動画に何が含まれているか分からせること。追加の構造化マークアップ必要)#SearchCentralLive pic.twitter.com/82JsdFj6yY
動画インデックス関連の問題の具体例
— TAHAYU (@tahayu55wd) June 16, 2023
動画は重要になってきますね#SearchCentralLive pic.twitter.com/SvgqkZyp7t
動画のインデックス登録で良くある問題の例を紹介していただきました#SearchCentralLive pic.twitter.com/g4B7U7swtc
— Polina Kogan/コガン ポリーナ (@PolinaKogan) June 16, 2023
動画検索について必ず把握しておいてほしい3点、とのこと#SearchCentralLive pic.twitter.com/TscFbBjlpQ
— Polina Kogan/コガン ポリーナ (@PolinaKogan) June 16, 2023
動画検索に必要なこと
— り (@ri7130) June 16, 2023
①動画ごとに専用のページを作成すること
②Googleが動画コンテンツファイルを取得できるようにすること(フェッチができるように)
③SeekToActionあるいはClipの構造化データマークアップを実装すること#SearchCentralLive
ファビコン(グーグル検索のビジュアル化)
Google検索の成長、どんどんビジュアル化が進んでいる#SearchCentralLive pic.twitter.com/mgvO5lmJqK
— Polina Kogan/コガン ポリーナ (@PolinaKogan) June 16, 2023
新たなショッピング特化のマークアップ。
— 長谷川 翔一 / 編集とマーケティング (@haseshout) June 16, 2023
1. 人気商品
2. 画材検索
3. ショッピングナレッジパネル
#SearchCentralLive pic.twitter.com/EHJAgsAPUg
ファビコンが正しく表示していない時の対処法
— ゆうき@未知株式会社 (@mchs_yuki) June 16, 2023
#SearchCentralLive pic.twitter.com/oih9EW4oGy
ファビコンが正しく出てるか確認しよう
— TAHAYU (@tahayu55wd) June 16, 2023
実装方法#SearchCentralLive pic.twitter.com/BwFNMZEFuH
Google Discover
Googleディスカバーでは大きな画像を使おう。クリック率が高まります。
— 長谷川 翔一 / 編集とマーケティング (@haseshout) June 16, 2023
実装方法は、メタタグを設置して、サイトマップを送ること。
#SearchCentralLive pic.twitter.com/heipAH2QWb
Googleディスカバーで大きな画像を表示させるにはmetaタグを追加する必要がある。ただし、画像が最低限大きめである必要がある。https://t.co/CpQxbanyEp#SearchCentralLive pic.twitter.com/LrYN93b1Qu
— ムラヤマ ユウスケ (@muraweb_net) June 16, 2023
ディスカバーで大きな画像にしたい場合は、<meta name ="robots" content="max-image-preview:large">
— り (@ri7130) June 16, 2023
#SearchCentralLive
Googleニュース
Googleニュースでは、適切な場所とフォーマットでニュースを提供したい。
— ムラヤマ ユウスケ (@muraweb_net) June 16, 2023
1つのニュースでも様々な媒体から提供されるため、コンテンツ内容からトピックを判断する。#SearchCentralLive pic.twitter.com/kaFumNRMQA
Google News Initiativeの3つの柱https://t.co/tMf0JgB2s0#SearchCentralLive pic.twitter.com/nhzVPMTLoS
— Polina Kogan/コガン ポリーナ (@PolinaKogan) June 16, 2023
グーグルニュースイニシアティブ(これかな?)https://t.co/cDmP8qHx6R
— り (@ri7130) June 16, 2023
▽わかりやすい方法でニュースを表示
・すべての人へトップニュース
・その人に向けてパーソナライズ
・関連コンテンツも探しやすく
#SearchCentralLive
関連性があり権威のあるニュースをピックアップするための仕組みはGoogle検索と同じで、クロール、インデックス、ランキング。
— ムラヤマ ユウスケ (@muraweb_net) June 16, 2023
特にクロール、インデックス面ではニュース専用の構造化データにより、コンテンツをコンポーネントとして理解しやすくなる。#SearchCentralLive
Googleニュースのランキングシステムはこちら!
— 長谷川 翔一 / 編集とマーケティング (@haseshout) June 16, 2023
“アルゴリズムは、コンテンツの関連性、注目度、鮮度、権威性、ユーザビリティ、ユーザーがクエリを行った場所、言語といった要因をチェックします”https://t.co/pS7MQYrq6S
#SearchCentralLive
ニュースは記事単位で評価。メタタグが大事。忘れないようにしないと。 #SearchCentralLive
— り (@ri7130) June 16, 2023
情報の信頼性
Googleとの出会いから話してくれる村上臣さん!
— Hiro Kano - SEOの人@Adobe (@hirokano123) June 16, 2023
「世界中の情報を整理し、世界中の人々がアクセスできて使えるようにすること」
途方もない課題
・全ての情報をIndexすべきではない
・誤った情報、スパムをフィルタリング
・正しい高品質情報をどう届けるか?#SearchCentralLive
情報の質
— Hiro Kano - SEOの人@Adobe (@hirokano123) June 16, 2023
・検索における高品質な情報とはなにか?
・検索セントラルに基本的な情報は公開している
→表示させたくない低品質コンテンツの定義は明記
・品質評価ガイドライン(英語)は一回読んでね
・検索の評価者と機械のハイブリットで品質改善に取り組んでいる#SearchCentralLive
正しくない情報の取り扱い
— Hiro Kano - SEOの人@Adobe (@hirokano123) June 16, 2023
・例えば「コロナワクチン 危険」などのクエリにはどんな情報を表示すべき?
・YMYL領域のクエリは公式サイト、公式情報を可能な限り優遇するようにしている
・ここの取り扱いはガイドラインに明記している。#SearchCentralLive
情報のリテラシー
— Hiro Kano - SEOの人@Adobe (@hirokano123) June 16, 2023
・情報の質も大事だが、最近はGoogleを情報を「確かめる」ために使う用途が増えてきている。
・そういった情報を落ち着いて調べるために、Google検索が使われている
参考記事:Snap Judgements; Reutershttps://t.co/RbX5C3FAdP#SearchCentralLive
怪しい情報に関して
— Hiro Kano - SEOの人@Adobe (@hirokano123) June 16, 2023
・検索結果にアラート表示させる取り組み行なっている
・GNIイニシアティブ:420億円投資して、メディアリテラシーやファクトチェックを行うプロジェクト
・32%の日本ユーザーがオンライン情報の嘘を見分ける自信が「まったくない」と回答している#SearchCentralLive
検索に出てくる「この結果について」の機能はユーザーに一旦立ち止まって検索結果について考えてもらいたいから。
— いながきですよ(サンクレイオ翼) (@IngkOsgt) June 16, 2023
それがユーザーの情報リテラシー向上にも繋がる。#SearchCentralLive
「コンテンツアドバイザリ」
— Polina Kogan/コガン ポリーナ (@PolinaKogan) June 16, 2023
状況が高速で変わる可能性がかる検索に対して「一旦落ち着いてください」という意味合いの結果#SearchCentralLive pic.twitter.com/WnbQsgDCSV
嘘や誤った情報を見分ける自信が「まったくない」と答える方が、日本では32%#SearchCentralLive pic.twitter.com/w9PE8QeRuY
— ムラヤマ ユウスケ (@muraweb_net) June 16, 2023
たくさんの情報が語られ、たくさんのツイートがあったため、ここでは拾いきれていない投稿もある。#SearchCentralLiveのハッシュタグでツイッターを探索してほしい。会場の雰囲気も感じられるだろう。
ちなみに、メイン司会のあんな氏に加えて、この春でグーグルを退社した金谷氏が1日限りでゲスト司会者として戻ってきてくれた。
本日は司会者として、Google のイベントに参加しています!Googleを退職してほぼ最初の仕事、最初のパプリックイベントです!ちょっと感慨深い。#SearchCentralLive https://t.co/Xcg04QgLnJ
— Takeaki Kanaya ★ 金谷 武明 (@jumpingknee) June 16, 2023
- すべてのWeb担当者 必見!
ページの動画が認識されない「視認性」の問題をSearch Consoleが説明するように 具体的な理由を3分類して提供 (グーグル 検索セントラル ブログ) 国内情報
ページの動画をグーグル検索が認識してくれない場合に、その理由を「視認性」の観点で教えてくれる機能が、Search Consoleに加わった。動画ページのインデックス登録レポートの機能改善だ。
視認性が低いと判断された動画は、インデックスされない。今回の改善では、視認性が低いと判定された理由を3種類に分けて説明するようになった。
3種類の分類と対処策は次のとおりだ:
動画がビューポートの外側にあります: 動画全体がページのレンダリング可能領域内にあり、そのページの読み込み時に表示されるよう動画の位置を変更します。
動画が小さすぎます: 動画の高さを 140 ピクセルより大きくするか、動画の幅を 140 ピクセルより大きくしてページ幅の 3 分の 1 以上にします。
動画の高さが高すぎます: 動画の高さを小さくして 1,080 ピクセル未満にします。
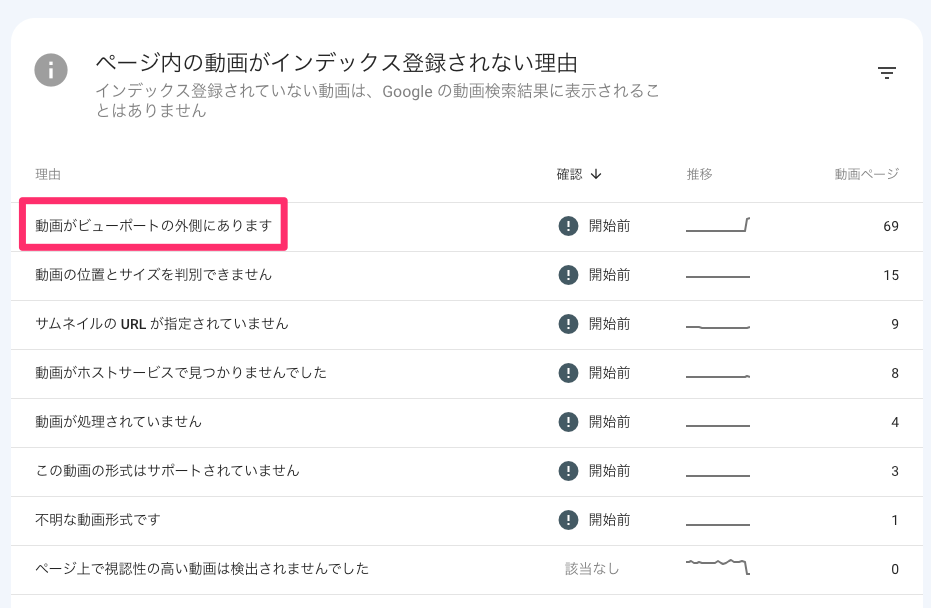
「視認性が高くない」と警告されても、具体的にどう対処すればいいのかわからないケースもあっただろう。今回の改善はトラブルシューティングの手助けになる。
- 動画が主要コンテンツなすべてのWeb担当者 必見!
- 「.store」ドメインのような新しいgTLDはグーグル検索で不利になるのか?
- 成人向けサイトではGooglebotの年齢を確認する必要なし
- noindexはインデックス制御、robots.txtはクロール制御
- Search Console一括データ エクスポートでびっくりな高額請求にならないための事前対策
- デジタル庁のサイトがちゃんと作られていて参考になるらしい
- Google、モバイル検索でPerspectivesフィルタを導入
- Google Bardがロケーション情報を取得し関連性がより高い回答を返すようになる
グーグル検索SEO情報②
「.store」ドメインのような新しいgTLDはグーグル検索で不利になるのか? ccTLDにするかgTLDにするかはターゲット国によって決める (Reddit) 海外情報
次の質問がReddit(レディット)のSEO掲示板に投稿された。
「.store」のドメイン名を取得しました。このドメイン名は、「.com」や、「.nl」「.fr」「.de」などの国別のドメイン名と比べるとグーグル検索のSEOで問題になるでしょうか?
グーグルのジョン・ミューラー氏が回答した:
まず気をつけなければいけないのは、ccTLDとgTLDの違いだ。
- ccTLD ―― 国コード別トップレベルドメイン。「.jp」「.nl」「.fr」「.de」など
- gTLD ―― ジェネリック(分野別)トップレベルドメイン。「.com」「.net」「.store」など
ccTLDは1つの国に焦点を当てる傾向があるが、次の場合には問題ない:
- その国で主に販売する予定である場合
- グローバルに販売する予定である場合
もしccTLDを使っているが別の国を主にターゲットにしたい場合(たとえば、今は「.de」のドメイン名だが、米国をターゲットにしたい場合)、その国のccTLDを新たに取得するか、gTLDを使うほうがいい。
新しいTLDのすべてはgTLDだ。参考までに言っておくと、一部は地域特化のようにみえるが、技術的にはそうではない(たとえば「.berlin」というトップレベルドメインがあるが、これはgTLDだ)。
SEOのためのccTLDとgTLDの違い以外にも、ユーザーの観点も考慮する必要がある。彼らは別の国のユーザー向けだと認識したリンクをクリックするだろうか?
日本の「.jp」や英国の「.uk」は、ccTLD(国別コードトップレベルドメイン)に分類される。グーグル検索ではその国のユーザーをターゲットにしていることを示すシグナルになる。英グーグル(google.co.uk)の検索結果では、たとえ英語サイトであっても「.co.jp」ドメイン名のサイトが(一般的なクエリで)上位表示することは稀だろう。したがって、特定に国のユーザーをターゲットにするなら、その国のccTLDを取得するのは理にかなっている。
一方で、「.com」や「.net」のように特定の国とは結びついていないトップレベルのドメイン名は、gTLD(分野別トップレベルドメイン)に分類される。また一部の国のccTLDは、グーグル検索ではgTLD扱いされる(たとえばツバルの「.tv」やアンギラの「.ai」など。gTLD扱いされるccTLDはこちらのドキュメントにリストがある)。
質問者が取得したという「.store」は新しいgTLDだ。新しいgTLDをグーグルは特別扱いせず、SEO的に有利にも不利にもなることはない。これはグーグルが公式に表明している(実際に、あまり行儀の良くないサイトが多い新gTLDのスパムECサイトが検索結果によくでていた時期もあった)。
- ホントにSEOを極めたい人だけ
成人向けサイトではGooglebotの年齢を確認する必要なし 素通りさせてかまわない (グーグル検索におけるセーフサーチとは) 国内情報
成人向けサイトやアルコール・タバコなど、コンテンツの閲覧に年齢確認を必要とするサイトに関係する技術ドキュメントの更新をお伝えする。
次の推奨が追加された:
Googlebot が年齢確認なしでクロールできるようにする
年齢確認が必須となっているコンテンツについては、年齢確認をトリガーすることなく Googlebot がコンテンツをクロールできるようにすることをおすすめします。これは、Googlebot のリクエストを確認し、年齢確認なしでコンテンツを提供することで可能です。
Googlebotがアクセスしたときは、確実にGooglebotであることを確認したうえで年齢確認なしにコンテンツを配信できる。こうすることで、年齢確認の要素によってクロールがブロックされることを防げる(こうした処理をしてもクローキング扱いにはならない)。
- 成人向けサイトのすべてのWeb担当者 必見!
noindexはインデックス制御、robots.txtはクロール制御 役割を混同しない (John Mueller on Twitter) 海外情報
ツイッターでの、グーグルのジョン・ミューラー氏とフォロワーのやり取りを紹介する。検索エンジンのクロール制御に関するものだ。
(フォロワー)あるページパラメータに「nofollow」と「noindex」の両方を追加した後も、Googlebotはこれらのページとパラメータをクロールし続けています。今後、Googlebotにこれらのページをクロールしないように指示する他の方法はありますか?
ミューラー氏は次のように回答した:
robots.txtはクロールを制御するもので、noindexはインデックスを制御するものだ。
robots.txt is for controlling crawling, noindex is for controlling indexing.
— John Mueller (official) · #StaplerLife (@JohnMu) May 31, 2023
ミューラー氏の言わんとしていることがおわかりだろうか?それぞれの仕組みの働きは次のとおりだ:
noindex ―― インデックスさせない(正確には、検索結果にでないようにする)
nofollow ―― そのページのリンクをGooglebotがたどらないようにする(URL発見やランキングシグナルとして利用させない)
robots.txtでのdisallow ―― 指定したURLをクロールさせない
noindexを指定しているページも、nofollowを指定しているページも、Googlebotはクロールする(そもそもクロールしなければ、これらの存在を認識できない)。
一方で、robots.txtでdisallow指定すればクロールを禁止することになり、ページの中身を読ませないようにできる(ただし、robots.txtでブロックしていてクロールできず中身も読めないページでも、URL自体はインデックスして検索結果にでてくることがある)。
質問者の目的がクロールの制御なのであれば、robots.txtで設定するのが正解だ(もし検索の対象にしたくないのであれば、noindex指定があることをグーグルが把握できるようにクロールは引き続きさせなければいけない)。
- ホントにSEOを極めたい人だけ
Search Console一括データ エクスポートでびっくりな高額請求にならないための事前対策 効率的な4つの構成を提案 (グーグル 検索セントラル ブログ) 国内情報
Search Consoleの一括エクスポートを利用すると、BigQueryにデータを日時でエクスポートできる。分析には非常に便利だ。
しかしBigQueryは、使い方によっては料金が発生し、思いがけずに高額になってしまうこともある。請求利用料金が高額になってしまわないようにするためには、「どんな状況で料金が発生するのか」「どうすれば費用を抑えられるのか」を知っておくといい。
Search ConsoleデータのBigQueryエクスポートに特化した効率的なデータの活用方法を、グーグルが検索セントラルブログで解説した。
次の4つの構成を提案している:
- 請求アラートと制限を作成する
- 元データに直接ダッシュボードを構築しない
- データ ストレージの費用を最適化する
- SQL クエリを最適化する
一括エクスポート機能を利用しているなら、詳細を元記事で確認してほしい。
内容が技術的でわかりにくい場合は、データ処理を担当している部署やパートナーにこの記事を添えて「ウチは大丈夫?」と確認するといいだろう。
- 一括エクスポート機能を利用しているすべてのWeb担当者 必見!
デジタル庁のサイトがちゃんと作られていて参考になるらしい 一見するとなんてことのないサイトだけれど (Qiita) 国内情報
デジタル庁のサイトは、一見するとなんということのない簡素なサイトに見えるのだが、分析すると実際には非常に精巧に構成されているそうだ。
次の点で、一般的なサイトとは一線を画しているとのことだ:
- 洗練されたシンプルさ、そしてデザイン
- JIS規格に沿ったウェブアクセシビリティ
- モダンなフロントエンド技術の採用
相当にスキルが高いウェブデザイナーが関わっていると推測される。ウェブサイトの設計とデザイン、構築に関わっている人は、元記事とそこからリンクされている資料を参考に、どこがどのようにスゴイのかを確認するといい。
- すべてのWeb担当者 必見!
- ウェブデザイナーに伝えましょう
海外SEO情報ブログの掲載記事からピックアップ
モバイル検索の新機能とBardの改良に関する記事をピックアップ。
- Google、モバイル検索でPerspectivesフィルタを導入
個人のクリエイターに焦点を当てたフィルタとのこと
- SEOがんばってる人用(ふつうの人は気にしなくていい)
- Google Bardがロケーション情報を取得し関連性がより高い回答を返すようになる
ローカルSEO戦略にも影響するか?
- SEOがんばってる人用(ふつうの人は気にしなくていい)
※このコンテンツはWebサイト「Web担当者Forum - 企業Webサイトとマーケティングの実践情報サイト - SEO・アクセス解析・SNS・UX・CMSなど」で公開されている記事のフィードに含まれているものです。
オリジナル記事:SEO達人の“検索意図”と“高品質なコンテンツ”の解説で、あなたのSEOをレベルアップ【SEO情報まとめ】 | 海外&国内SEO情報ウォッチ
Copyright (C) IMPRESS CORPORATION, an Impress Group company. All rights reserved.

